I have always been gravitated towards the idea of tech debt. So not surprisingly, recently I found myself meditating over data debt.
Data debt is the sinister cousin of tech debt
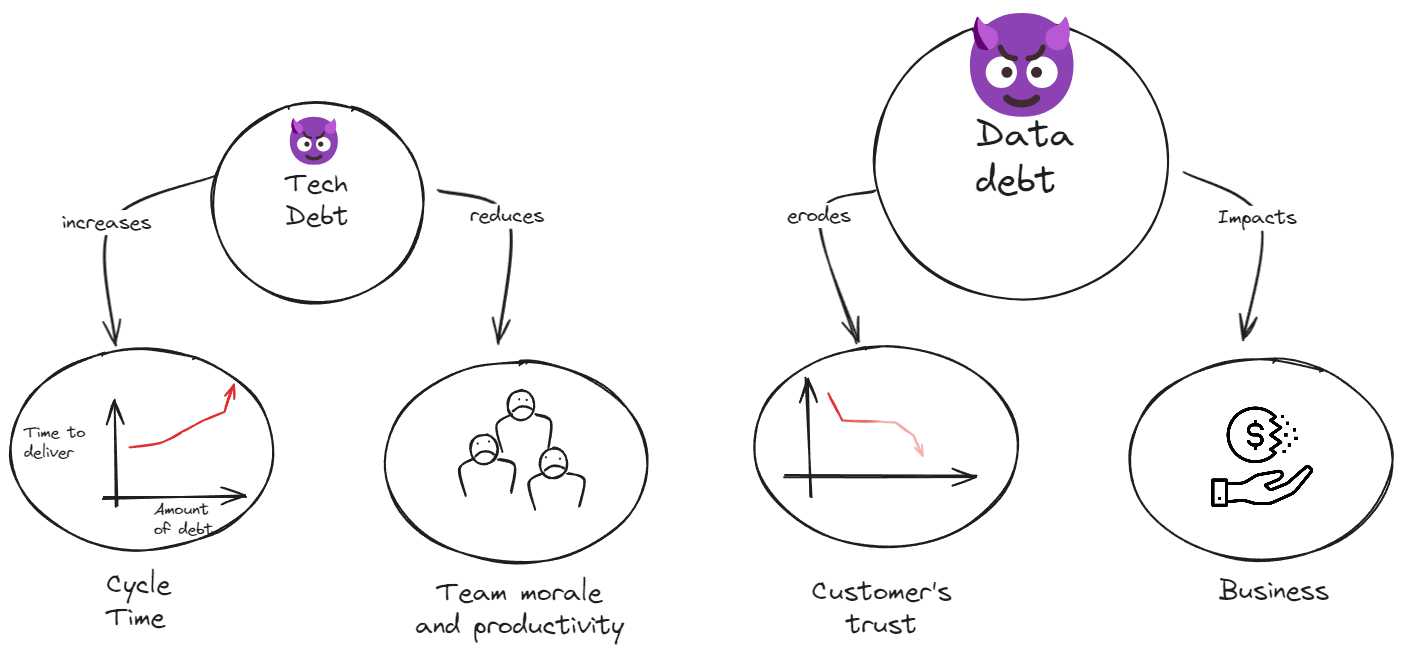
Data debt, a much sinister cousin of tech debt - can have far graver impact than the latter. So much so that I believe we might need a different metaphor for it.
Tech debt is local, data debt leaks to customer
While tech debt is local to the product delivery team, something that erodes predictability and hampers developer experience. Data debt on other hand can potentially erode customer trust and hamper business! It's a monster of another scale
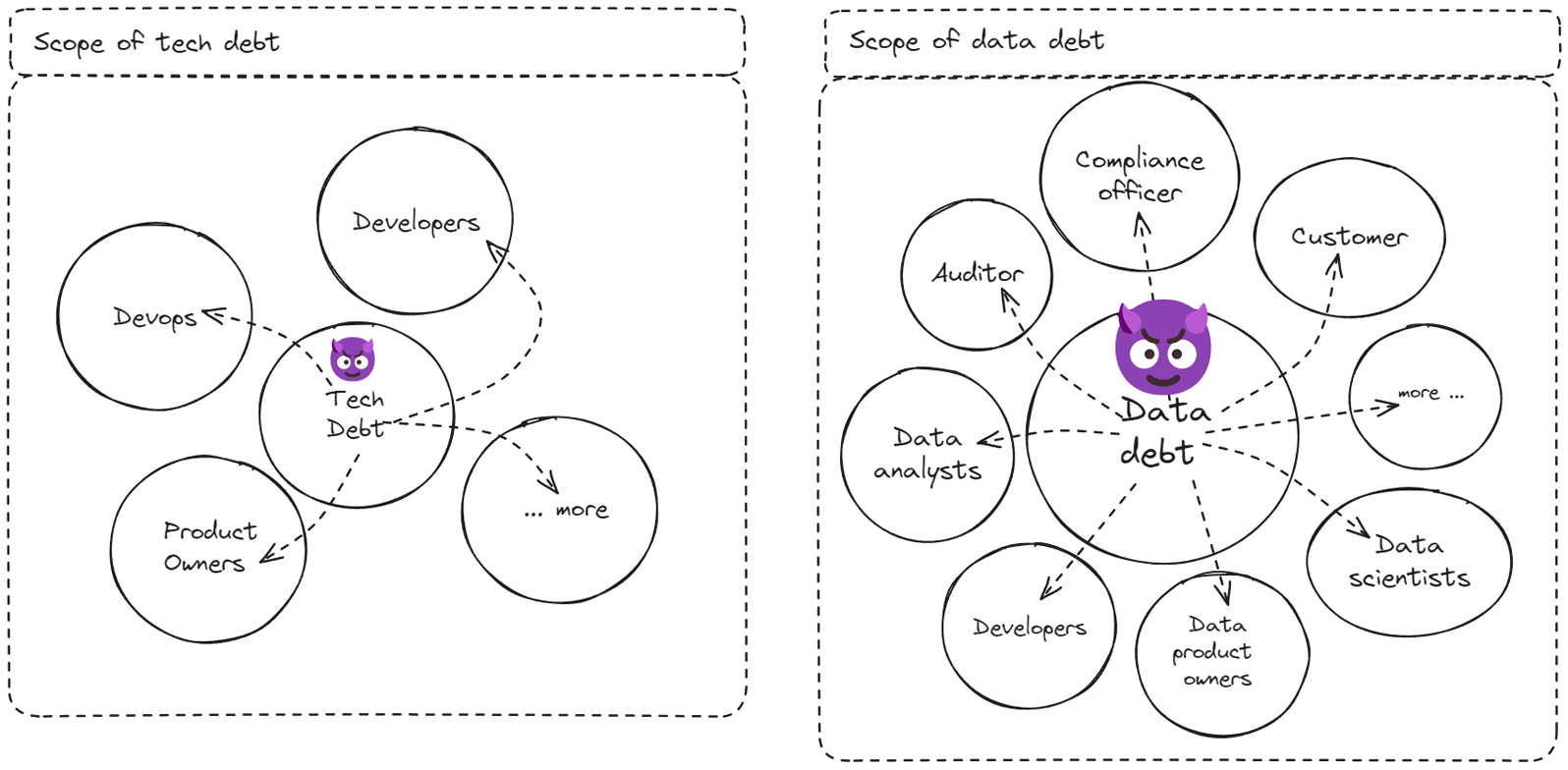
the scope and surface area of data debt is just larger. One reason is because there are more data worker personas, and the debt can impacts each persona differently.
What is Data debt
Its accumulation of (intentional or an unintentional) shortcomings introduced in the data system that erodes quality, and trust in data or a part of the data system, hence directly impacting atleast one of the data worker or worse, an end user.
Who are these data workers? Well we have your truly, the data engineer. But the data debt impacts machine learning engineer bit differently. It impacts data analyst differently. It impacts BI developer differently etc
Data debt growth over time
Another dimension to consider about data debt is how it has grown over the last decade or so. I believe when the world had mostly monolithic deployments, the data model was guided by extensive ER modeling.
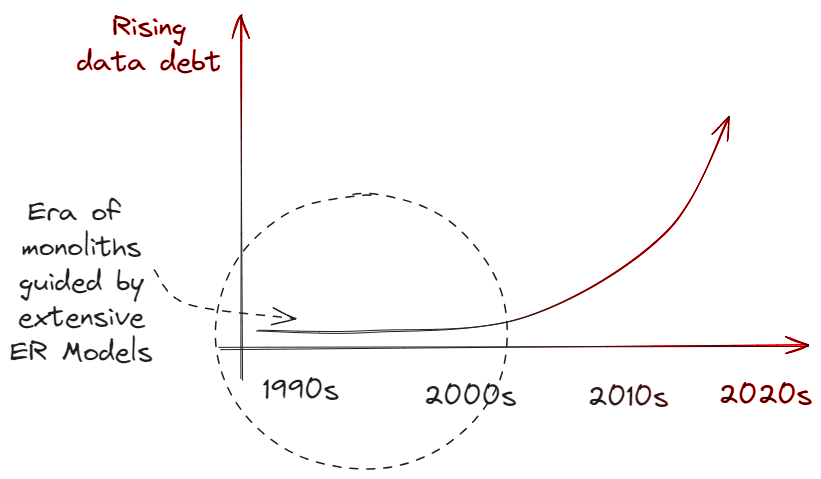
I'm reminded of my mentor's comment back in late 2013 - 'Dhruv', he said. 'the work has changed so much. Just couple of years ago, the walls were covered in large DB diagrams, and now they're invisible'
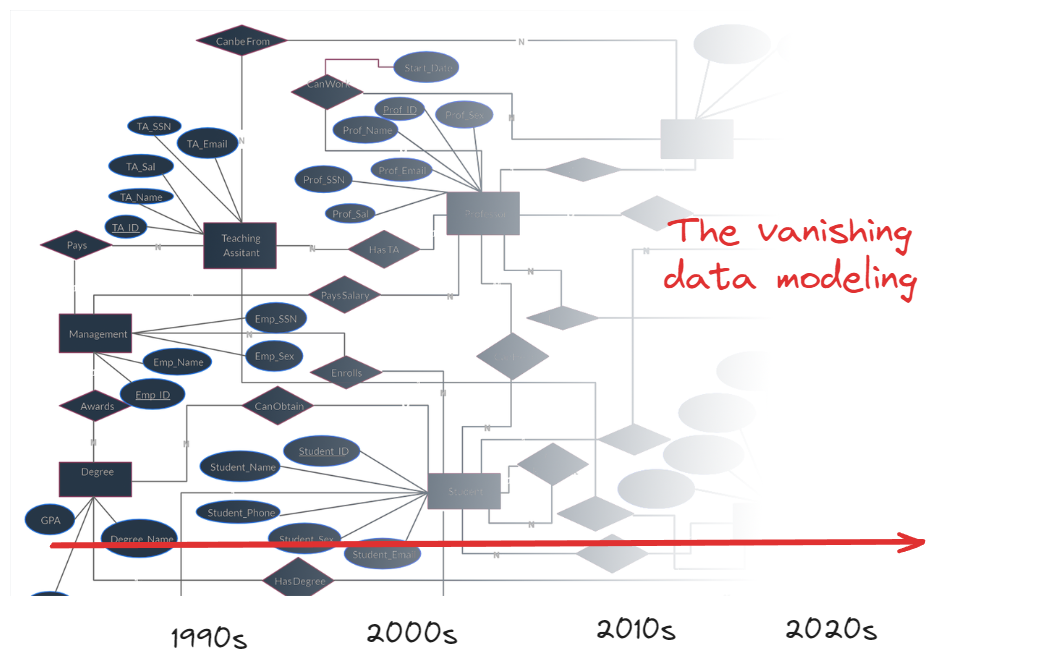
Data debt is difficult to encapsulate
I guess he was talking about the problem in making - the data architecture just couldn't keep pace with the product cycle times. Product development had a way to control the impact of tech debt, to an extent each can be contained within its own microservice.
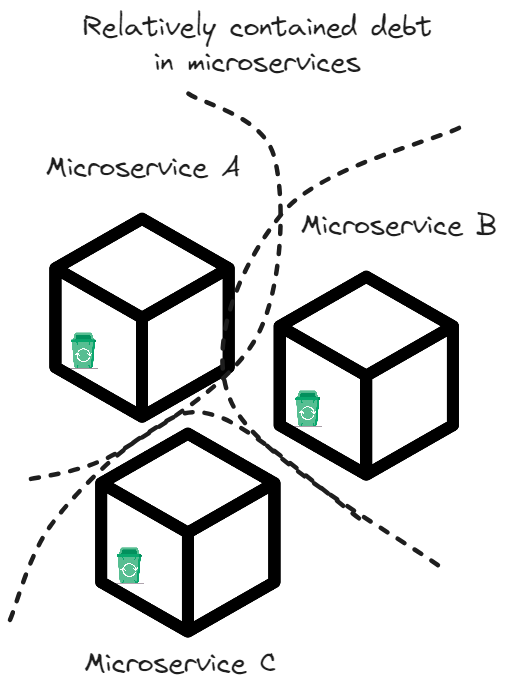
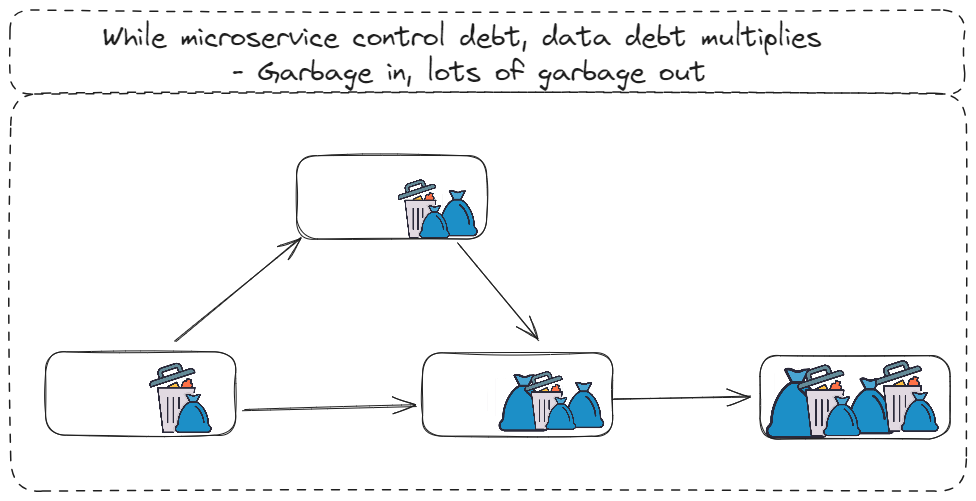
But data debt, is a monster of another scale. Since the value of data is derived by joining or in other words when its complete, any potential problems just keep multiplying throughout this data value stream pipeline.
Identification of debt
However during the decade of growth at all costs, data modeling had been degraded to a 2nd class citizen. And almost a decade later, the enterprise experiences all kind of related pains. To identify this pain or debt, one can look at 3 lens - functional, operational and structural.
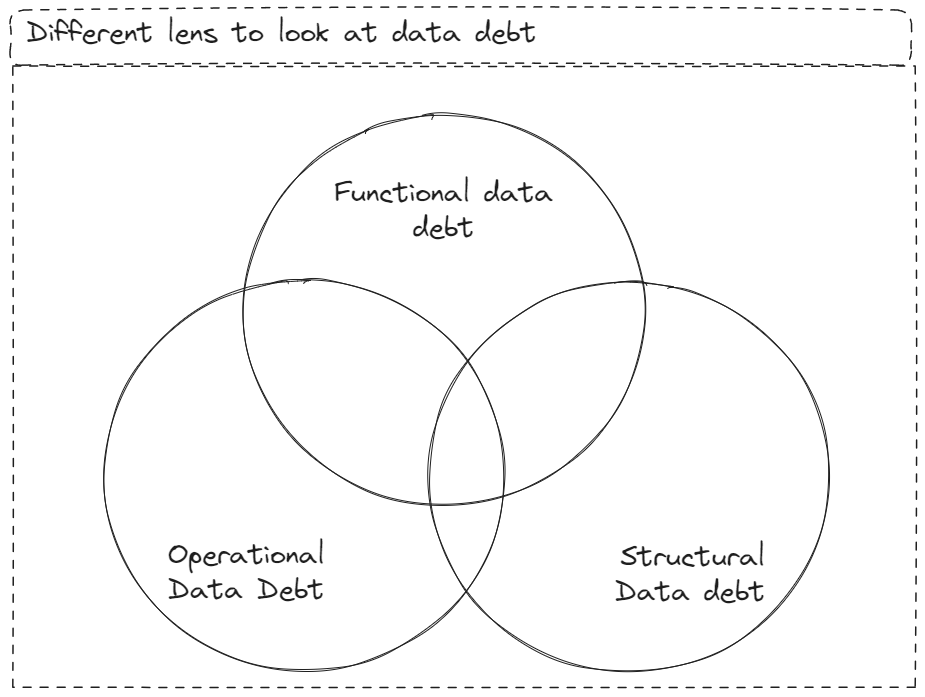
Functional data debt will lead to bugs, as they somehow compromise with the accuracy of the system. These impact customer directly. Missing data, incorrect data, insufficient test cases or lack of data contracts - are all examples of functional debt.
Operational debt impacts a cross functional requirement - like dead or unused data wasting space, or under-utilized computing resources wasting money. Or poor handling of PII data causing issues with compliance.
Structural debt impacts some kind of data value creator - be it data engineer, machine learning engineer or analyst. Lack or outdated documentation, duplication, overly complex ETL or transformations - all this impacts cycle time, job satisfaction etc
Tracking and acting on data debt
The word tech debt was likely motivated from financial industry. A debt has principal and an interest rate. The principal is the cost of original decision, the interest rate is rather floating and changes with requirements.
Some debt is virtually free, and other is a very high interest loan - a hotspot in code that changes frequently. Hence I believe that quantifying tech debt as a single metric (number of days it'll take to fix it) is not really helpful.
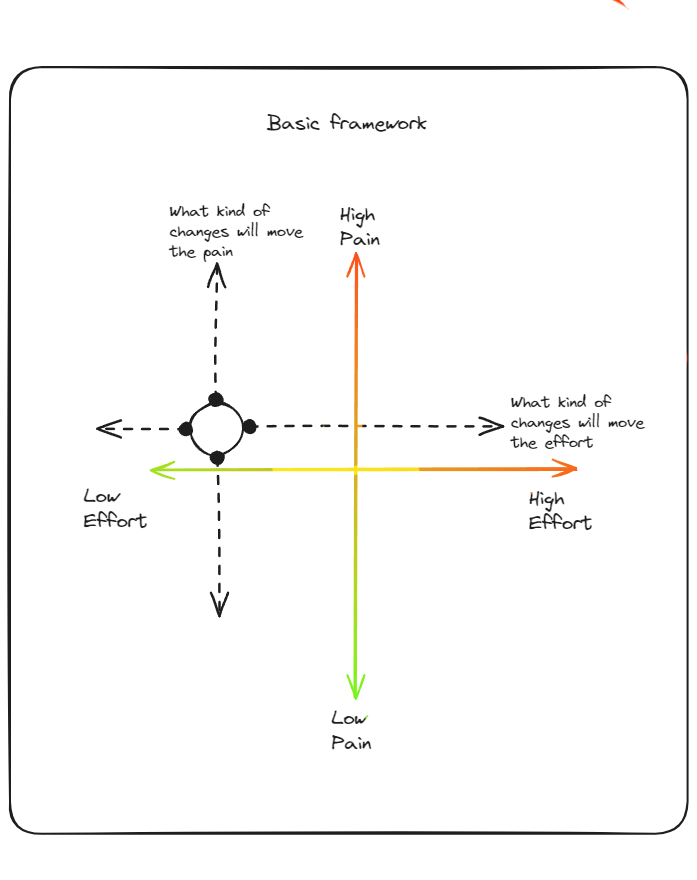
However tracking and prioritizing amongst conflicting priorities remains a key. A useful framework I have seen for prioritsing traditional tech debt is classifying them on a plane - one axis of pain, and one axis of effort.
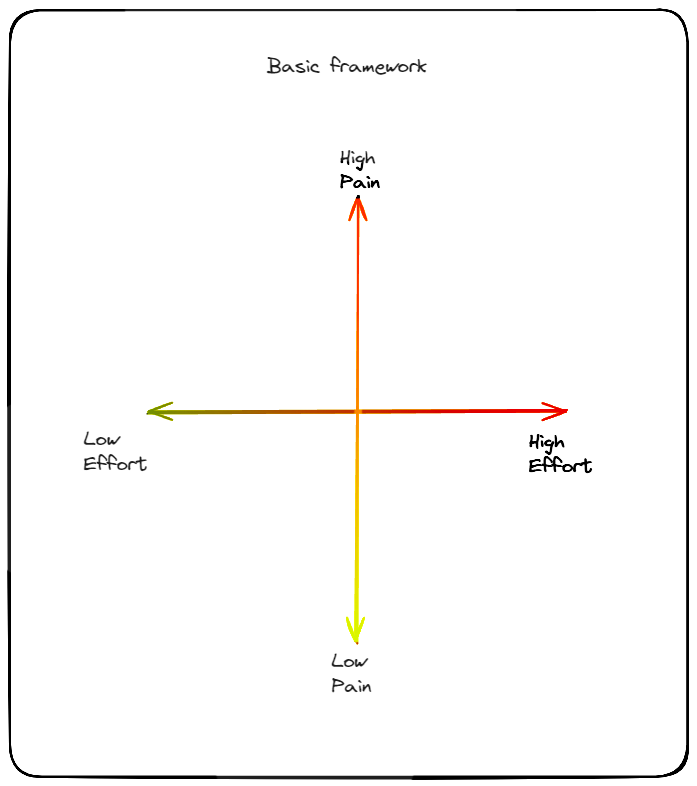
Since data debt is more multi faceted than tech debt - I recommend extending this framework to classify per role or atleast per lens.
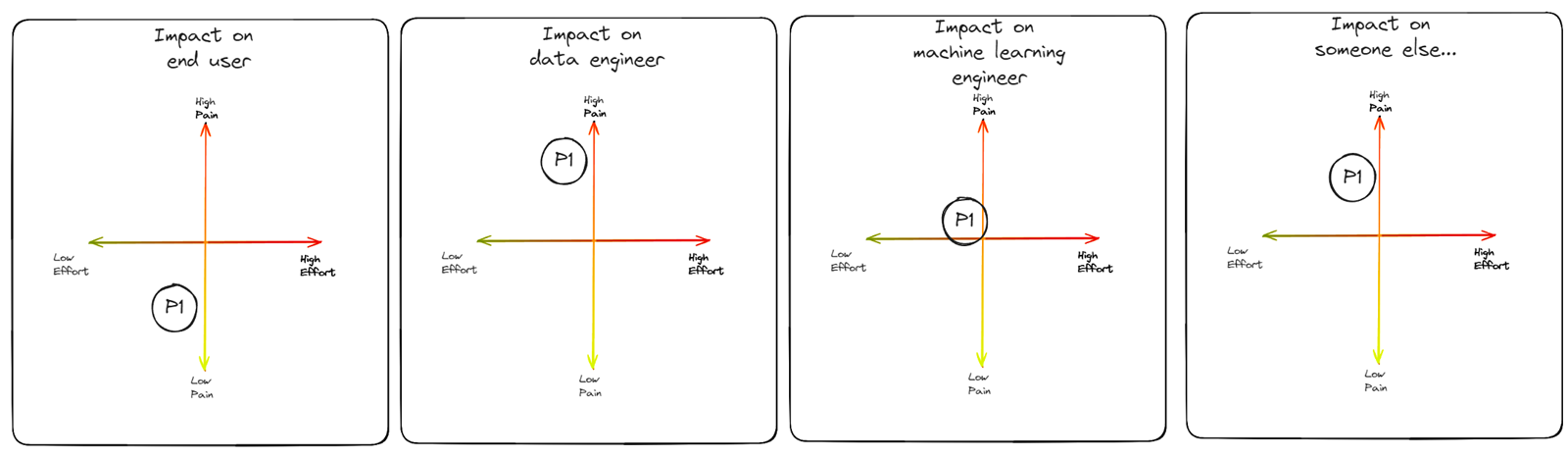
Another useful inquiry is what kind of requirement pressure (during the sprint, or quarter) will shuffle the debt into other quadrant - this conversation will give visibility to business on what kind of changes will be hard.
Concluding thoughts
In conclusion - Don't ignore data debt. If data is oil, data debt is contamination. At some point in time unaddressed data debt can bring the running enterprise to a halt!
Data debt, like tech debt will always exist. We need to identify it, track its impact & address it accordingly. We need better tools to assist with this monstrous task. Addressing this in sprint, providing dedicated bandwidth & having conversations around it will be a good start